Unicode
Avant Unicode, les 128 premiers caractčres ASCII étaient communs 0..127 et les suivants 128..255 spécifiques ŕ chaque langue ou pays. Un code page par pays rendait impossible la tenue de documents ŕ la fois en français, grec, russe, arabe, et en langues asiatiques, voire męme impossible du norvégien, allemand et français.
Unicode est une norme permettant d'encoder les caractčres utilisés dans les langues écrites du monde entier, ainsi que leur ponctuation et symboles.
Pour plus de précisions allez voir sur www.unicode.org
Est-ce une simple coďncidence, mais l'Amiga était déjŕ en avance sur son temps męme au niveau de son charset. Le Latin-1, ou ISO 8859 Set 1 est exactement le męme que la police en rom topaz. Ni Windows, ni Apple, ni un autre systčme n'ont ce charset.
Comme les caractčres U+0000 U+00FF sont déjŕ dans le systčme, on peut récupérer des fichiers UTF-8 ou unicode en Français, ou latin-1 rien qu'en supprimant les 00 en trop et en remplaçant les autres caractčres par '?', signifiant que l'on ne peut pas les encoder, car pour les autres caractčres, cela se complique.
UCODE

Ucode est certainement le seul moyen de pouvoir afficher des caractčres unicode sur Amiga, OS3.1 et plus requis.
Pour utiliser Ucode, il faut au moins 4Mo de mémoire, un disque dur (25Mo pour tous les glyphes d'aminet) et
au moins un 68000 (oui un 68000!!)
sur Aminet text/show/ucode.lha
Que contient Ucode ?
Un programme principal sous forme de bibliothčque
ucode.library
Un jeu de caractčre de base (Glyphs) qui peut ętre enrichi par d'autres (Ucode Glyph Packs au nombre de 9)
De la documentation
Ucode.guide
Des programmes utilitaires
UcodeFix (en cas d'ajout/retrait de glyphes)
FontMaker (pour générer des glyphes ŕ partir d'une police)
GlyphEditor (pour fabriquer des glyphes point par point)
Des programmes de démonstration
GlyphViewer
SampleStrings
Des programmes de démonstration en assembleur 68000.
Des scripts de démonstration ARexx.
Vous constaterez qu'il manque les includes pour le langage C,
mais ils existent ŕ un autre endroit sur Aminet dev/c/C_UCode.lha
Le GlyphEditor permet d'éditer des caractčres pour un jeu de taille 8, MN Normal, TT TéléType, comme topaz 8.
Ici j'édite le delta russe U+0414, heu pardon, le caractčre "CYRILLIC CAPITAL LETTER DE"
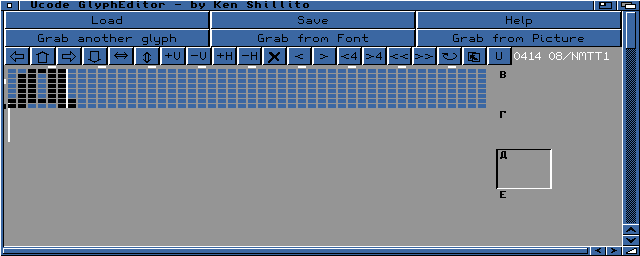
Ce Glyphpack est disponible sur Aminet text/show/UCodeTopaz8.lha
Bref Ucode est un bon début pour pouvoir compléter la police topaz de base... avec le programme UReader qui suit.
UReader
UReader est disponible sur Aminet dev/c/UReader.lha
UReader est capable d'afficher n'importe quel fichier ASCII en Latin-1, Unicode little endian, Unicode big endian, et UTF-8.
Il y a deux versions. UReaderTTEngine (ttengine.library) et UReader (ucode.library).
Ces deux programmes ont chacun leurs points forts et points faibles, et m'ont servi pour choisir un moteur de base (pour faire comme Wordpad pour Windows :) voire mieux).
UReaderTTEngine
+ true type (du monde windows)
- La ttengine.library ne fonctionne qu'avec un 68020 et plus.
- Les fontes true type sont rarement complčtes.
- Fontes proportionelles et lissées, illisibles en faible résolution.
UReader
+ fonctionne sur un 68000.
- il faut ętre patient pour voir les pages s'afficher.
- seule une fonte en corps 11 est disponible.
Un petit essai d'encadrement et divers symboles
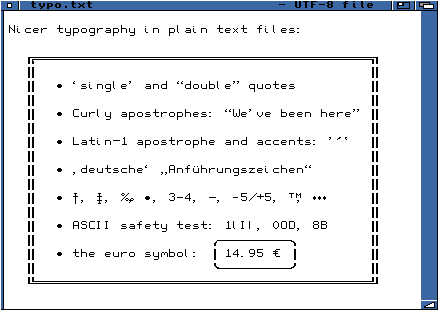 |
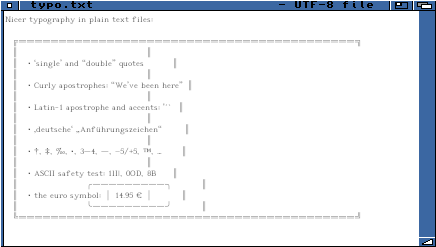 |
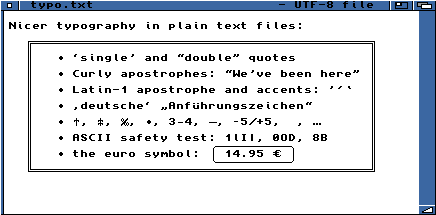 |
| Sans Serif SS 11 |
fonte true type |
Topaz TT 8 |
Des signes phonétiques.
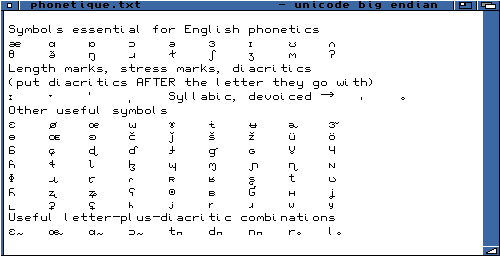 |
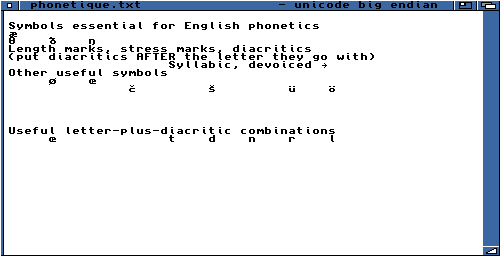 |
| Sans Serif SS 11 |
Topaz TT 8 (topaz 8) Il manque beaucoup de lettres!! |
Quelques bribes de russe
 |
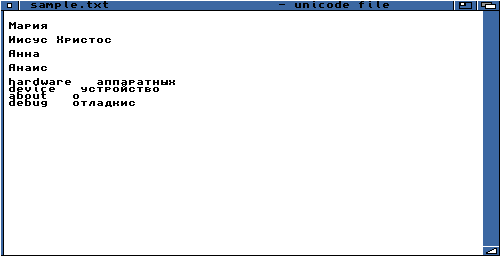 |
| Sans Serif SS 11 |
Topaz TT 8 (topaz 8) |
Conclusion
On a de quoi s'amuser sur Amiga classic, maintenant que l'on peut afficher des textes Unicode, il ne reste plus qu'ŕ créer un éditeur de textes...